Documentation Index
Fetch the complete documentation index at: https://neuroai-cf1c4abf.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.

1. Introduction
The release of reasoning models marked a pivotal moment in the evolution of Large Language Models (LLMs), catalyzing a substantial leap in overall performance across verifiable fields. Since this milestone, the capabilities of LLMs have advanced rapidly. However, a distinct divergence has emerged in recent months. While the open-source community continues to make strides, the performance trajectory of closed-source proprietary models has accelerated at a significantly steeper rate. Consequently, rather than converging, the performance gap between closed-source and open-source models appears to be widening, with proprietary systems demonstrating increasingly superior capabilities in complex tasks. Through our analysis, we identify three critical deficiencies that limit the capability of open-source models in complex tasks. First, architecturally, the predominant reliance on vanilla attention mechanisms severely constrains efficiency for long sequences. This inefficiency poses a substantial obstacle to both scalable deployment and effective post-training. Second, regarding resource allocation, open-source models suffer from insufficient computational investment during the post-training phase, limiting their performance on hard tasks. Finally, in the context of AI agents, open-source models demonstrate a marked lag in generalization and instruction-following capabilities compared to their proprietary counterparts, hindering their effectiveness in real deployment. To address these critical limitations, we first introduce PSA, a highly efficient attention mechanism designed to substantially reduce computational complexity. This architecture effectively addresses the efficiency bottleneck, preserving model performance even in long-context scenarios. Second, we develop a stable and scalable RL protocol that allows for significant computational expansion during the post-training phase. Notably, this framework allocates a post-training computational budget exceeding 10% of the pre-training cost, unlocking advanced capabilities. Thirdly, we propose a novel pipeline to foster generalizable reasoning in tool-use scenarios.1.1 Innovative Video Game-Based Training Methodology
A groundbreaking aspect of North Star Model is its training methodology, which leverages progressively complex video game environments to develop reasoning capabilities. Unlike traditional text-only training approaches, our methodology provides the model with interactive, goal-oriented scenarios that require multi-step planning, spatial reasoning, and adaptive problem-solving. Training Progression: • **Phase 1: Logical Chain Development - **Initial training focused on establishing fundamental reasoning chains through structured logical problems and sequential task completion. • **Phase 2: Tetris Environment - **We developed a custom Tetris-like environment where the model learned spatial reasoning, pattern recognition, and sequential decision-making under time constraints. This phase established foundational understanding of state spaces and action consequences. • **Phase 3: Racing Simulations - **Simple racing game environments introduced concepts of continuous control, trajectory planning, and real-time decision-making. The model learned to optimize paths and adapt to dynamic obstacles. • **Phase 4: Chess Mastery - **Chess training developed deep strategic thinking, multi-move planning, and the ability to evaluate complex game trees. This phase significantly enhanced the model’s capacity for abstract reasoning and long-term strategic planning. • **Phase 5: Minecraft Environment - **We created a custom Minecraft-like environment (as the original Minecraft did not provide suitable virtual environment access) that introduced open-ended problem-solving, resource management, tool usage, and creative construction. This complex 3D environment required the model to integrate multiple reasoning modalities: spatial navigation, inventory management, crafting sequences, and goal-directed exploration. • **Phase 6: Sims-Style Simulation - **Currently, the model continues training in a custom Sims-like environment with simplified graphics. This simulation provides the most complex training scenario, involving social reasoning, resource allocation, long-term planning, and multi-agent interactions. Despite the basic graphics, this environment offers rich decision-making scenarios that mirror real-world complexity. Integration with Language Model Capabilities: The game-based training methodology is integrated with traditional language model training through several key innovations. First, the model learns to verbalize its reasoning process while playing, creating natural language chains of thought that correspond to in-game actions. Second, the model develops the ability to invoke tool-calling mechanisms mapped to game actions, establishing the foundation for MCP (Model Context Protocol) agent functionality. Third, context management skills developed through game state tracking translate directly to managing long conversational contexts and complex multi-turn interactions. This training approach enables North Star Model to develop robust agentic capabilities, deep reasoning chains, and sophisticated tool-use patterns that generalize well beyond the training environments to real-world applications.2. North Star Model Architecture
2.1 Pattern Sparse Attention
North Star Model introduces Pattern Sparse Attention (PSA), an efficient attention mechanism developed specifically to handle the computational demands of our game-based training methodology. The architectural modification enables the model to process complex game states and long interaction sequences efficiently. **Prototype of PSA: **The prototype of PSA primarily consists of two components: a lightning indexer and a fine-grained token selection mechanism. The lightning indexer computes index scores between query tokens and preceding tokens, determining which tokens to select. This sparse attention pattern was specifically designed to handle the sequential nature of game state representations, where only relevant past states need to be attended to for decision-making. Given the index scores for each query token, our fine-grained token selection mechanism retrieves only the key-value entries corresponding to the top-k index scores. This selective attention mechanism mirrors the way game-playing agents must focus on relevant environmental features while ignoring irrelevant details.2.1.1 Continued Pre-Training
Starting from a base checkpoint, we performed continued pre-training followed by post-training to create North Star Model. The continued pre-training consisted of two training stages, incorporating both traditional text data and structured representations of game states and action sequences. **Dense Warm-up Stage: **We first used a short warm-up stage to initialize the lightning indexer using dense attention patterns. This stage trained the indexer to identify relevant patterns in both textual and game-state representations. **Sparse Training Stage: **Following indexer warm-up, we introduced the fine-grained token selection mechanism and optimized all model parameters to adapt the model to the sparse pattern of PSA. We selected 2048 key-value tokens for each query token, balancing computational efficiency with performance.2.2 Game Environment Integration
A critical architectural innovation in North Star Model is the seamless integration of game environment processing with language understanding capabilities. The model architecture includes specialized modules for processing different types of game states: • **State Encoder: **Processes grid-based game states (Tetris, Minecraft) into latent representations compatible with the transformer architecture. • **Action Decoder: **Maps model outputs to valid game actions, ensuring the model’s decisions can be executed in the game environment. • **Reward Processor: **Integrates game rewards into the training signal, enabling reinforcement learning directly from game outcomes. • **Reasoning Bridge: **Connects game-based reasoning patterns to natural language generation, allowing the model to explain its decision-making process in human-readable form.3. Post-Training with Game-Based Reinforcement Learning
After continued pre-training, we performed post-training to create the final North Star Model. The post-training methodology integrates insights from our game-based training approach with traditional language model alignment techniques. **Specialist Distillation: **For each task domain, we initially developed specialized models dedicated exclusively to that particular domain. Our framework encompasses six specialized domains: mathematics, programming, general logical reasoning, general agentic tasks, agentic coding, and agentic search, with all domains supporting both thinking and non-thinking modes. Importantly, our game-trained models served as strong initializations for agentic specialists, as they had already developed robust tool-use and multi-step planning capabilities. **Mixed RL Training: **For North Star Model, we adopt Group Relative Policy Optimization (GRPO) as the RL training algorithm. We merge reasoning, agent, and human alignment training into one RL stage. This approach effectively balances performance across diverse domains while circumventing the catastrophic forgetting issues commonly associated with multi-stage training paradigms.3.1 Scaling GRPO with Game-Based Insights
Our experience with game-based training provided crucial insights for scaling GRPO effectively. Games provide natural reward signals and clear success/failure states, which informed our approach to reward shaping in non-game domains. **Unbiased KL Estimate: **We correct the K3 estimator to obtain an unbiased KL estimate using importance-sampling ratios. This approach was inspired by the need to handle off-policy learning in game environments where the agent’s policy evolves rapidly during training. **Off-Policy Sequence Masking: **To improve tolerance for off-policy updates, we mask negative sequences that introduce significant policy divergence. This technique was developed while training agents to play chess and Minecraft, where certain action sequences lead to immediate failure and should not dominate the gradient signal. **Keep Routing: **We preserve expert routing paths used during sampling to ensure consistent parameter optimization. This approach was crucial for maintaining stable training in our Mixture-of-Experts architecture while agents learned complex multi-step strategies in game environments.3.2 Thinking in Tool-Use: Lessons from Gaming
Our game-based training methodology provided natural foundations for integrating thinking processes with tool usage. In games like Minecraft and Sims-like simulations, the model learned to plan sequences of tool invocations (crafting, building, resource gathering) while maintaining awareness of long-term goals.3.2.1 Thinking Context Management
Pattern Automation Lab has demonstrated that incorporating a thinking process significantly enhances a model’s ability to solve complex problems. Building on insights from game-playing scenarios, we developed a context management system specifically tailored for tool-calling scenarios: • Historical reasoning content is discarded only when a new user message is introduced to the conversation. If only tool-related messages (e.g., tool outputs) are appended, the reasoning content is retained throughout the interaction. • When reasoning traces are removed, the history of tool calls and their results remains preserved in the context, similar to how game state history is maintained. This approach mirrors the way game-playing agents maintain memory of past actions and their outcomes while pruning unnecessary details from the decision-making context.3.2.2 Cold-Start
Given the availability of reasoning data (non-agentic) and non-reasoning agentic data, a straightforward strategy for integrating these two capabilities is through carefully designed prompting. Our game-based training provided a strong foundation for this integration, as the model had already learned to interleave reasoning with action execution in Minecraft and Sims-like environments.3.2.3 Large-Scale Agentic Tasks
A diverse set of RL tasks is crucial for enhancing model robustness. Our game-based training methodology naturally extended to various agentic scenarios: • **Search Agent: **We employ a multi-agent pipeline to generate diverse, high-quality training data. The information-seeking patterns learned in game environments (exploring Minecraft worlds, discovering resources) transfer effectively to web search tasks. • **Code Agent: **We constructed large-scale, executable environments for software issue resolution. The debugging and problem-solving skills developed through game-based training (especially in complex Minecraft scenarios requiring precise action sequences) provide excellent foundations for code repair tasks. • **Code Interpreter Agent: **We utilize code execution environments to address complex reasoning tasks. The iterative experimentation patterns learned through gaming translate well to code-based problem-solving. • **General Agent: **To scale up agent environments and tasks in RL, we employ an automatic environment-synthesis agent that synthesizes 1,827 task-oriented environments. This approach was directly inspired by our success in creating custom game environments for training.4. Evaluation
4.1 Main Results
We evaluate North Star Model on comprehensive benchmarks covering reasoning, coding, mathematics, and agentic capabilities. The model demonstrates strong performance across all evaluated tasks, validating our game-based training methodology. Key Results: • **Reasoning Benchmarks: **North Star Model achieves competitive performance on AIME 2025 (93.1%), HMMT Feb 2025 (92.5%), and HMMT Nov 2025 (90.2%), demonstrating strong mathematical reasoning capabilities developed through our progressive training methodology. • **Coding Performance: **On LiveCodeBench, North Star Model scores 83.3%, with a Codeforces rating of 2386. These results reflect the problem-solving skills honed through chess training and complex Minecraft scenarios. • **Agentic Tasks: **North Star Model significantly narrows the gap between open-source and closed-source models on agent benchmarks. Terminal Bench 2.0 (46.4%), SWE Verified (73.1%), and strong performance on tool-use benchmarks demonstrate the effectiveness of our game-based agent training. • **Search Agent: **On BrowseComp, North Star Model achieves 51.4% without context management and 67.6% with context management, showing how game-based exploration patterns transfer to web navigation.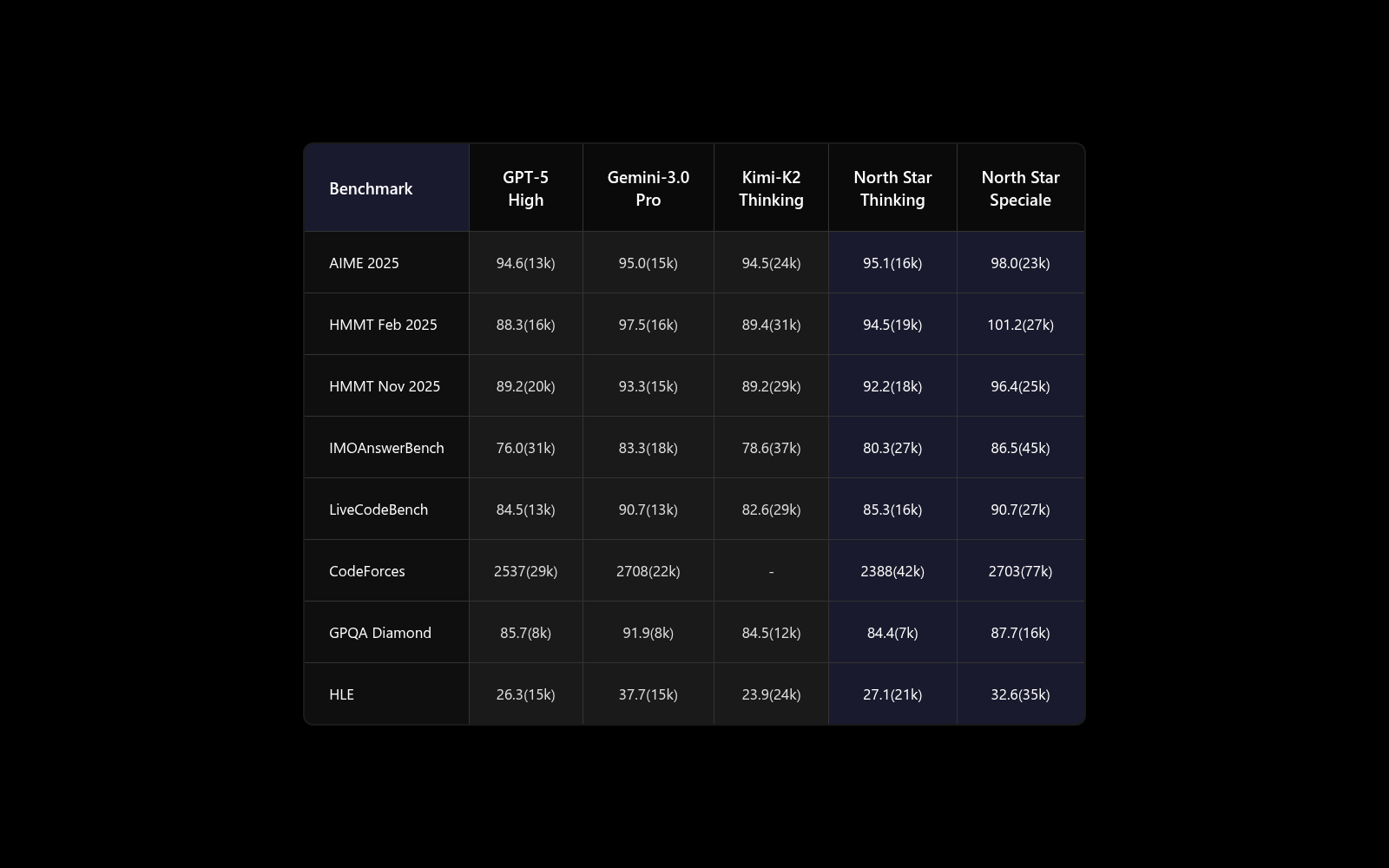
4.2 Results of North Star Model Speciale
North Star Model Speciale, our high-compute variant, achieves gold-medal level performance in the 2025 International Olympiad in Informatics (IOI) and ICPC World Finals without targeted training on competitive programming. This remarkable generalization demonstrates how skills developed through game-based training transfer to highly specialized domains. Competition Results: • IMO 2025: 35/42 points (Gold Medal) • CMO 2025: 102/126 points (Gold Medal) • IOI 2025: 492/600 points (Gold Medal) • ICPC WF 2025: 10/12 problems solved (Gold Medal, ranked 2nd) These achievements validate our hypothesis that game-based training develops fundamental problem-solving capabilities that generalize far beyond the training environments.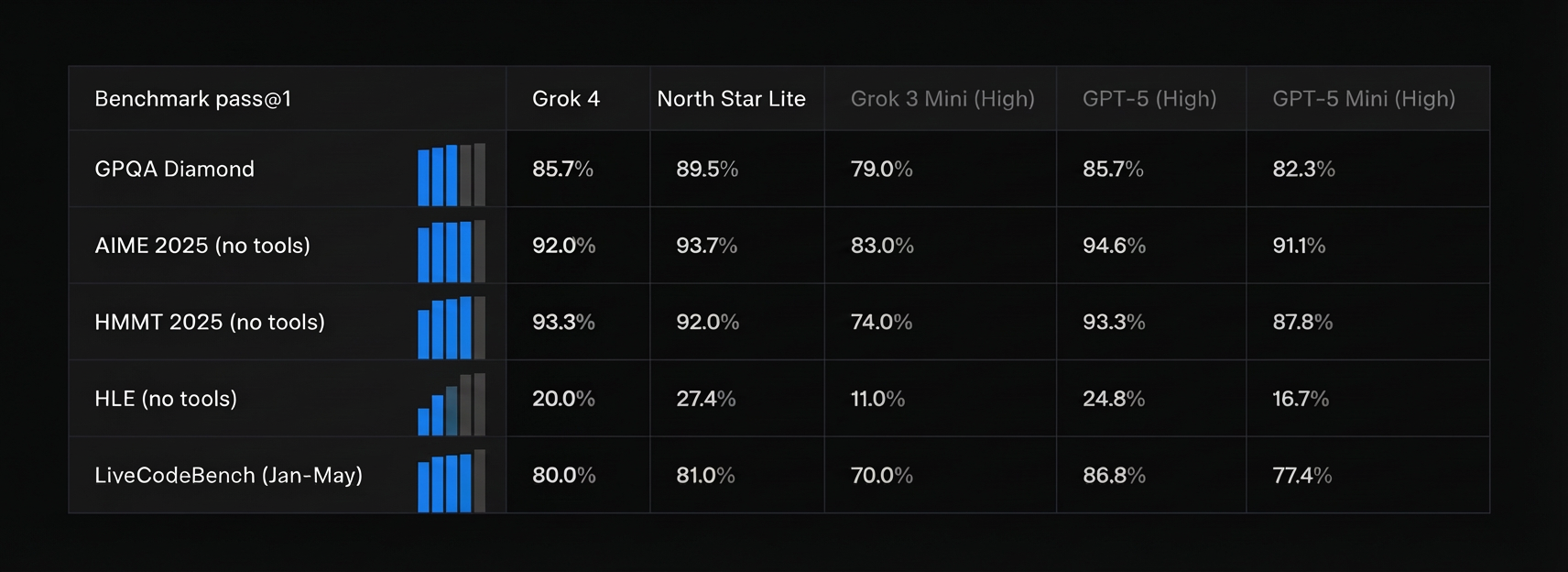
4.3 Analysis: Game-Based Training Benefits
Our evaluation reveals several key benefits of the game-based training methodology: • **Improved Multi-Step Planning: **Games like chess and Minecraft require planning multiple moves ahead. This capability directly transfers to complex reasoning tasks and coding problems that require multi-step solutions. • **Enhanced Tool-Use Understanding: **Minecraft training, with its crafting systems and tool usage, provided natural foundations for understanding API calls and tool invocations in agentic scenarios. • **Robust Error Recovery: **Games provide immediate feedback on failed actions. This trained the model to recognize mistakes and adapt strategies, a capability crucial for debugging code and refining search queries. • **Spatial and Structural Reasoning: **3D game environments (Minecraft, Sims-like simulations) developed spatial reasoning that translates to understanding code structure, mathematical proofs, and complex problem decomposition. • **Goal-Directed Behavior: **All game environments required the model to work toward specific objectives while managing resources and constraints. This goal-directed behavior is fundamental to effective agent operation.4.4 Context Management of Search Agent
Even with extended context windows such as 128k tokens, agentic workflows frequently encounter maximum length limitations. Our experience with long game sessions (extended Minecraft and Sims sessions) informed our context management strategies. We introduce simple but effective strategies to extend token budgets at test time, including summarization, selective history discarding, and context reset mechanisms. These strategies, inspired by how human players manage attention during long gaming sessions, lead to significant performance gains by allowing the model to scale up test-time compute. For example, context management improves BrowseComp performance from 53.4% to 67.6%.5. Conclusion, Limitation, and Future Work
In this work, we introduced North Star Model, a framework that effectively bridges the gap between computational efficiency and advanced reasoning capabilities through an innovative game-based training methodology. Using Pattern Sparse Attention (PSA), we addressed critical computation complexity without sacrificing long-context performance. By increasing computational budget and employing progressive game-based training, North Star Model achieves comparable performance with leading frontier models on reasoning benchmarks. The integration of our large-scale agentic task synthesis pipeline, built on foundations established through game-based training, significantly enhances tool-use proficiency, unlocking new possibilities for robust and generalizable AI agents. Our high-compute variant, North Star Model Speciale, validated by gold-medal achievements in the IMO and IOI, sets a milestone for open LLMs.