Documentation Index
Fetch the complete documentation index at: https://neuroai-cf1c4abf.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.

1. Introduction
The release of reasoning models marked a pivotal moment in the evolution of Large Language Models (LLMs), catalyzing a substantial leap in overall performance across verifiable fields. Since this milestone, the capabilities of LLMs have advanced rapidly. However, a distinct divergence has emerged in recent months. While the open-source community continues to make strides, the performance trajectory of closed-source proprietary models has accelerated at a significantly steeper rate. Through our analysis at Pattern Automation Lab, we identify three critical deficiencies that limit the capability of open-source models in complex tasks. First, architecturally, the predominant reliance on vanilla attention mechanisms severely constrains efficiency for long sequences. Second, regarding resource allocation, open-source models suffer from insufficient computational investment during the post-training phase. Finally, in the context of AI agents, open-source models demonstrate a marked lag in generalization and instruction-following capabilities compared to their proprietary counterparts. To address these critical limitations, Pattern Automation Lab developed North Star Model with three key innovations: first, Pattern Sparse Attention (PSA), a highly efficient attention mechanism; second, a stable and scalable RL protocol that allocates over 10% of pre-training cost to post-training; and third, advanced context engineering principles derived from building production AI agent systems.1.1 Innovative Video Game-Based Training Methodology
A groundbreaking aspect of North Star Model is its training methodology, which leverages progressively complex video game environments to develop reasoning capabilities. Unlike traditional text-only training approaches, our methodology provides the model with interactive, goal-oriented scenarios that require multi-step planning, spatial reasoning, and adaptive problem-solving. Training Progression: • **Phase 1: Logical Chain Development - **Initial training focused on establishing fundamental reasoning chains through structured logical problems. • **Phase 2: Tetris Environment - **Custom Tetris-like environment for spatial reasoning and sequential decision-making. • **Phase 3: Racing Simulations - **Simple racing games for continuous control and trajectory planning. • **Phase 4: Chess Mastery - **Chess training for deep strategic thinking and multi-move planning. • **Phase 5: Minecraft Environment - **Custom Minecraft-like environment for open-ended problem-solving, resource management, and tool usage. • **Phase 6: Sims-Style Simulation - **Ongoing training in a custom Sims-like environment with simplified graphics, providing complex social reasoning scenarios.Abstract We introduce North Star Model, a model that harmonizes high computational efficiency with superior reasoning and agent performance. The key technical breakthroughs of North Star Model are as follows: (1) Pattern Sparse Attention (PSA): We introduce PSA, an efficient attention mechanism that substantially reduces computational complexity while preserving model performance in long-context scenarios. (2) Scalable Reinforcement Learning Framework: By implementing a robust reinforcement learning protocol and scaling post-training compute, North Star Model performs comparably to leading frontier models. Notably, our high-compute variant, North Star Model Speciale, surpasses comparable models and exhibits reasoning proficiency achieving gold-medal performance in both the 2025 International Mathematical Olympiad (IMO) and the International Olympiad in Informatics (IOI). (3) Advanced Context Engineering: We developed sophisticated context management techniques optimized for production AI agents, focusing on KV-cache optimization, attention manipulation, and robust error recovery. (4) Large-Scale Agentic Task Synthesis Pipeline: To integrate reasoning into tool-use scenarios, we developed a novel synthesis pipeline that systematically generates training data at scale. **Novel Training Methodology: **North Star Model employs an innovative training approach using simulated video game environments, progressing from simple logical tasks through increasingly complex interactive scenarios. This game-based training methodology enables the model to develop robust reasoning chains, spatial understanding, and multi-step planning capabilities through direct interaction with dynamic virtual environments.
1. Introduction
The release of reasoning models marked a pivotal moment in the evolution of Large Language Models (LLMs), catalyzing a substantial leap in overall performance across verifiable fields. Since this milestone, the capabilities of LLMs have advanced rapidly. However, a distinct divergence has emerged in recent months. While the open-source community continues to make strides, the performance trajectory of closed-source proprietary models has accelerated at a significantly steeper rate. Through our analysis at Pattern Automation Lab, we identify three critical deficiencies that limit the capability of open-source models in complex tasks. First, architecturally, the predominant reliance on vanilla attention mechanisms severely constrains efficiency for long sequences. Second, regarding resource allocation, open-source models suffer from insufficient computational investment during the post-training phase. Finally, in the context of AI agents, open-source models demonstrate a marked lag in generalization and instruction-following capabilities compared to their proprietary counterparts. To address these critical limitations, Pattern Automation Lab developed North Star Model with three key innovations: first, Pattern Sparse Attention (PSA), a highly efficient attention mechanism; second, a stable and scalable RL protocol that allocates over 10% of pre-training cost to post-training; and third, advanced context engineering principles derived from building production AI agent systems.1.1 Innovative Video Game-Based Training Methodology
A groundbreaking aspect of North Star Model is its training methodology, which leverages progressively complex video game environments to develop reasoning capabilities. Unlike traditional text-only training approaches, our methodology provides the model with interactive, goal-oriented scenarios that require multi-step planning, spatial reasoning, and adaptive problem-solving. Training Progression: • **Phase 1: Logical Chain Development - **Initial training focused on establishing fundamental reasoning chains through structured logical problems. • **Phase 2: Tetris Environment - **Custom Tetris-like environment for spatial reasoning and sequential decision-making. • **Phase 3: Racing Simulations - **Simple racing games for continuous control and trajectory planning. • **Phase 4: Chess Mastery - **Chess training for deep strategic thinking and multi-move planning. • **Phase 5: Minecraft Environment - **Custom Minecraft-like environment for open-ended problem-solving, resource management, and tool usage. • **Phase 6: Sims-Style Simulation - **Ongoing training in a custom Sims-like environment with simplified graphics, providing complex social reasoning scenarios.2. North Star Model Architecture
2.1 Pattern Sparse Attention
North Star Model introduces Pattern Sparse Attention (PSA), an efficient attention mechanism developed specifically to handle the computational demands of our game-based training methodology. The architectural modification enables the model to process complex game states and long interaction sequences efficiently. **Prototype of PSA: **The prototype of PSA primarily consists of two components: a lightning indexer and a fine-grained token selection mechanism. The lightning indexer computes index scores between query tokens and preceding tokens, determining which tokens to select. This sparse attention pattern was specifically designed to handle the sequential nature of game state representations.3. Advanced Context Engineering for Production AI Agents
Pattern Automation Lab’s development of North Star Model required sophisticated context engineering techniques to achieve production-grade performance. Our research team discovered that proper context management is as critical as model architecture for real-world agent deployment. This section presents the fundamental principles of context engineering developed through extensive experimentation with North Star Model.3.1 The Strategic Choice: In-Context Learning
At the inception of North Star Model development, Pattern Automation Lab faced a fundamental choice: train an end-to-end agentic model using open foundations or build an agent atop the in-context learning capabilities of frontier models. Our experience showed that in-context learning offers crucial advantages: • Rapid iteration cycles measured in hours rather than weeks • Orthogonality to base model progress - improvements in foundation models directly benefit our system • Flexibility to adapt to changing requirements without retraining This strategic decision shaped North Star Model’s architecture around optimizing in-context learning rather than parameter tuning. If model progress is a rising tide, North Star Model is designed to be a boat, not a pole stuck in the seabed.3.2 Core Principle 1: Designing Around KV-Cache
KV-cache hit rate is the single most important metric for production AI agents, directly impacting both latency and cost. Pattern Automation Lab’s experiments with North Star Model revealed that proper KV-cache optimization can reduce costs by 10x and dramatically improve response times.3.2.1 Agent Operational Principles
After receiving user input, North Star Model executes a chain of tool invocations: • The model selects an action from a predefined action space based on current context • The action executes in the environment (virtual sandbox) • The result is added to context as an observation • The cycle repeats until task completion Context grows with each step while output (structured function calls) remains short. In North Star Model deployments, the average input-to-output token ratio is 100:1.3.2.2 Economic Benefits of KV-Cache
Contexts with identical prefixes can utilize KV-cache, dramatically reducing Time To First Token (TTFT) and inference costs. For example, with leading model providers: • Cached tokens: $0.30/MTok • Uncached tokens: $3.00/MTok • 10x cost difference3.2.3 Key KV-Cache Optimization Practices
1. Prompt Prefix Stability Due to the autoregressive nature of LLMs, even a single token difference invalidates the cache. Pattern Automation Lab developed strict guidelines: • Avoid timestamps at the beginning of system prompts • Ensure deterministic serialization of all context elements • Maintain consistent ordering in JSON serialization 2. Append-Only Context North Star Model maintains an append-only context structure: • Never modify previous actions or observations • Guarantee stable key ordering in JSON serialization • Treat context as an immutable log of interactions 3. Explicit Cache Break Points • Some providers require manual insertion of cache break points • Account for potential cache expiration in long-running sessions • Include the end of system prompt in break points3.3 Core Principle 2: Tool Masking Instead of Removal
3.3.1 The Action Space Growth Problem
As North Star Model’s capabilities expanded, the number of available tools grew exponentially. The popularity of protocols like MCP (Model Context Protocol) exacerbates this issue. User-provided tools can reach hundreds, leading to: • Incorrect action selection • Inefficient solution paths • Degraded overall agent performance3.3.2 Problems with Dynamic Tool Management
Attempts at dynamic tool addition/removal create two critical problems: **Problem 1: KV-Cache Invalidation - **Tool definitions reside at the beginning of context. Any changes invalidate cache for all subsequent actions. **Problem 2: Model Confusion - **References to removed tools in previous actions lead to schema violations and hallucinations.3.3.3 Solution: Context-Aware State Machine
Pattern Automation Lab developed a logit masking approach for North Star Model instead of tool removal. The system maintains three function-calling modes: • **Auto: **Model may choose to call a function or not • **Required: **Model must call a function (choice unconstrained) • **Specified: **Model must call a function from a defined subset Action name prefixes enable grouping: • browser_* - browser tools • shell_* - command line tools • file_* - file system operations3.4 Core Principle 3: Filesystem as Extended Context
3.4.1 Context Window Limitations
Modern LLMs offer 128K+ token context windows, but in agentic scenarios, problems arise: • Massive observations when working with unstructured data (web pages, PDFs) • Performance degradation beyond certain context lengths • High cost of long inputs even with prefix caching3.4.2 Recoverable Compression Strategy
Pattern Automation Lab treats the filesystem as the ultimate context for North Star Model: • Unlimited size • Persistent by nature • Direct agent control North Star Model learns to use the filesystem as structured external memory. Compression strategies are always recoverable - content can be excluded from context as long as access to the source (URL, file path) is preserved. **Implications for State Space Models: **Efficient file memory may be key for State Space Models (SSMs). Unlike transformers, SSMs lack full attention but can compensate by externalizing long-term state, potentially becoming successors to Neural Turing Machines.3.5 Core Principle 4: Attention Manipulation Through Repetition
3.5.1 The Goal Drift Problem
A typical task in North Star Model requires approximately 50 tool invocations. In long cycles, the agent is vulnerable to: • Topic drift • Forgetting early goals • Lost-in-the-middle context problems3.5.2 Goal Repetition Strategy
Pattern Automation Lab implemented a systematic approach where North Star Model continuously updates a todo.md file, repeating goals at the end of context. This approach: • Places global plan in recent attention range • Avoids lost-in-the-middle problems • Reduces goal misalignment • Uses natural language for focus without architectural changes3.6 Core Principle 5: Preserving Error Traces
3.6.1 The Importance of Error Recovery
Agents inevitably make mistakes: • Language model hallucinations • Runtime errors • Misbehavior of external tools • Unexpected edge cases3.6.2 Learning from Errors Strategy
A common impulse is to hide errors (clear trace, retry action), but this removes evidence for adaptation. Pattern Automation Lab’s research showed that an effective approach is to leave wrong turns in context. When North Star Model sees a failed action and resulting observation, it: • Implicitly updates internal beliefs • Shifts priority away from similar actions • Reduces probability of repeating the mistake Error recovery is one of the clearest indicators of true agentic behavior.3.7 Core Principle 6: Avoiding the Few-Shot Trap
3.7.1 The Over-Imitation Problem
Few-shot prompting can backfire in agentic systems. Language models are excellent imitators, and context full of similar action-observation pairs leads to: • Mechanical pattern following • Drift in repetitive tasks • Over-generalization • Hallucinations3.7.2 Solution: Structured Diversity
Pattern Automation Lab introduces controlled variation in North Star Model: • Different serialization templates • Alternative phrasings • Minor noise in order and formatting Principle: The more uniform the context, the more brittle the agent becomes.3.8 Integration with Game-Based Training
These context engineering principles were refined through North Star Model’s game-based training. Video game environments provided natural testing grounds for context management strategies: • **Minecraft Environment: **Long crafting sequences naturally required append-only context and KV-cache optimization • **Sims-Like Simulation: **Complex multi-character scenarios validated goal repetition and attention manipulation strategies • **Chess Training: **Strategic planning validated error preservation and learning from mistakes4. Evaluation
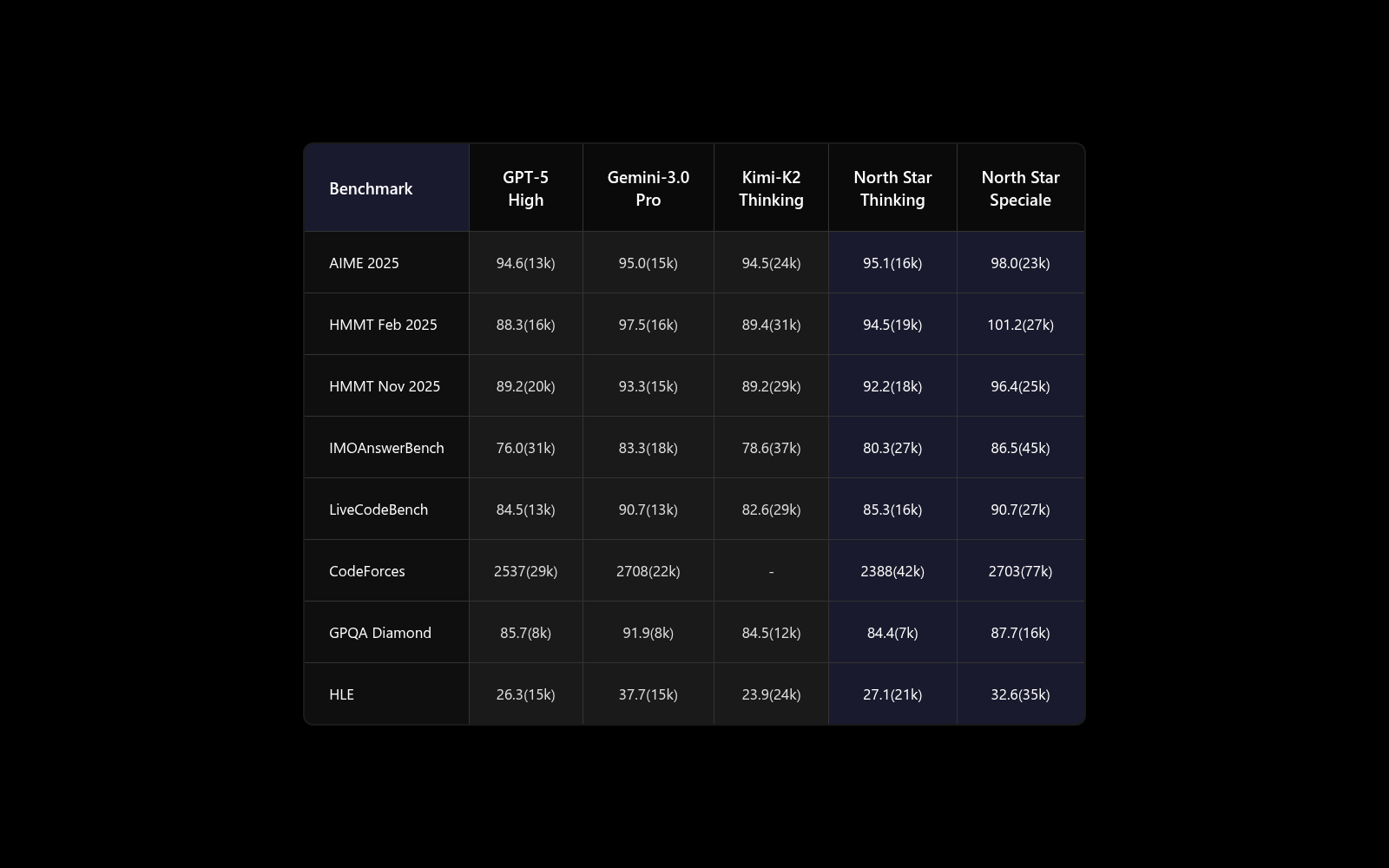
4.1 Main Results
We evaluate North Star Model on comprehensive benchmarks covering reasoning, coding, mathematics, and agentic capabilities. The model demonstrates strong performance across all evaluated tasks, validating both our game-based training methodology and advanced context engineering.