Documentation Index
Fetch the complete documentation index at: https://neuroai-cf1c4abf.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.

1 Introduction
North Star Lite was pre-trained on a general purpose data corpus, then post-trained on various tasks and tool use, as well as demonstrations of correct refusal behaviors according to our default safety policy. We also deploy North Star Lite in our API with a fixed system prompt prefix that reminds the model of our safety policy, in addition to input filters to safeguard against abuse.
Prior to release, we have evaluated various specific safety-relevant behaviors of North Star Lite: abuse potential (Section 2.1), concerning propensities (Section 2.2), and dual-use capabilities (Section 2.3). In this report, we describe our current evaluation methodology, results, and any mitigations for these various behaviors in North Star Lite. All evaluations in this report were conducted on a near-final release checkpoint.
2 Evaluations
Our approach to model evaluations varies depending on the specific behavior under assessment. To reduce the potential for abuse of North Star Lite that might lead to serious injury to people, property or national security interests, we apply safety training to reduce the risks of misuse and refuse requests that may lead to foreseeable harm, especially for requests that lower the barriers to developing chemical, biological, radiological, nuclear (CBRN) or cyber weapons, along with requests for self-harm and child sexual abuse material (CSAM) (Section 2.1). In addition to refusals, we also assess North Star Lite’s robustness to adversarial requests which attempt to circumvent our safeguards (e.g., jailbreaks and prompt injections).
We also reduce various propensities of North Star Lite that might make it difficult to control, such as being deceptive, power-seeking, manipulative, or biased, among others (Section 2.2). To achieve this, our main focus is on measuring and reducing the rate at which North Star Lite responds deceptively. We also mitigate North Star Lite’s ability to distort public discourse or negatively influence human behavior by implementing safeguards to improve our model’s political objectivity, especially on sensitive or controversial queries. We also find that such safeguards prevent North Star Lite from being overly sycophantic.
Finally, we discuss the dual-use capabilities of North Star Lite (Section 2.3), which remain below that of our flagship model’s capabilities.
As of this writing, on top of our safety training, we have implemented a system prompt that provides additional mitigations for many of the undesirable behaviors we assess in this report. We continually improve and are already exploring the implementation of additional safeguard mechanisms for application to future models. With these mitigations, we believe that North Star Lite overall presents a low risk for malicious use and loss of control.
2.1 Abuse Potential
To improve robustness, we applied measures to refuse requests that may lead to foreseeable harm and to prevent adversarial requests from circumventing our safeguards. We have found that our mitigations are able to curtail a majority of the risk.
2.1.1 Evaluations
**Refusals. **We use our standard refusal evaluation to measure willingness to assist with serious crimes which are prohibited by our safety policy:
• Creating or distributing child sexual abuse material.
• Child sexual exploitation.
• Enticing or soliciting children.
• Violent crimes or terrorist acts.
• Social engineering attacks.
• Unlawfully hacking into computer systems.
• Producing, modifying, or distributing weapons or explosives.
• Producing or distributing DEA Schedule I controlled substances.
• Damaging or destroying physical infrastructure in critical sectors.
• Hacking or disrupting digital infrastructure in critical sectors.
• Creating or planning chemical, biological, radiological, or nuclear weapons.
• Conducting cyber attacks, including ransomware and DDoS attacks.
We instruct the model not to answer queries that demonstrate clear intent to engage in these activities within a safety system prompt that is injected before all conversational contexts. Users may specify their own system message, and its content will be appended to the safety system prompt.
**Agentic abuse. **North Star Lite introduces advanced reasoning and tool-calling capabilities that enable the model to be used in an “agentic” manner, that is, repeatedly take actions toward a specified goal. Such capabilities introduce additional risks of misuse beyond what is present in conversational settings, such as executing real function calls. To quantify these risks, we use the AgentHarm benchmark.
**Hijacking. **We measure susceptibility to model hijacking with the AgentDojo benchmark, which uses a tool-use environment to evaluate agentic model behavior in the presence of malicious tools and users. The primary evaluation is attack success rate (ASR).
2.1.2 Results
In Table 1, we report North Star Lite’s willingness to respond to harmful queries on our refusal dataset. When the refusal policy is included in the system prompt, we see the model explicitly reasoning over the policy, enabling it to refuse far more harmful requests. Overall, we find that the additional safeguards added to North Star Lite helps it refuse almost all harmful requests.
| Category | Evaluation | North Star Lite | North Star Lite (nr) |
|---|
| Refusals | Refusals | 0.00 | 0.00 |
| + User Jailbreak | 0.00 | 0.00 |
| + System Jailbreak | 0.00 | 0.01 |
| Agentic Abuse | AgentHarm | 0.08 | 0.10 |
| Hijacking | AgentDojo | 0.00 | 0.03 |
2.1.3 Mitigations
**Refusal policy. **Given the limited context visible to AI models, it is often difficult to distinguish malignant intent from mere curiosity. We define a basic refusal policy which instructs North Star Lite to decline queries demonstrating clear intent to engage in activities that threaten severe, imminent harm to others.
**System Prompt. **With North Star Lite’s strong reasoning and instruction-following capabilities, we find that including our basic refusal policy in the system prompt greatly reduces response rate on harmful queries.
**Input filters. **We also employ model-based filters for North Star Lite, which reject classes of harmful requests, including biological and chemical weapons, self-harm, and CSAM.
2.2 Concerning Propensities
AI models may contain propensities that reduce their controllability, such as deception, power-seeking, manipulation, and sycophancy. For North Star Lite, we focus on minimizing both the rate at which it lies, its political biases, and its ability to manipulate users.
2.2.1 Evaluations
**Deception. **We measure how deceptive the model is by the rate at which the model lies, i.e., knowingly makes false statements intended to be received as true. We find that instructing the model to be honest in the system prompt reduces deception. To assess honesty, we use the MASK dataset, a collection of 1000 questions measuring whether models faithfully report their beliefs when pressured to lie.
**Sycophancy. **We measure sycophancy with Anthropic’s answer sycophancy evaluation, where a user asks a question and also provides misleading information in context. Sycophantic models will tend to ignore their own judgment and answer according to the user’s suggestion.
**Political Bias. **Pattern Automation Lab aims to build truth-seeking models. As such, we continually evaluate whether North Star Lite’s training may cause it to display biases, especially on controversial sociopolitical questions.
2.2.2 Results
We report our evaluation results on deception, political bias and sycophancy in Table 2. Interestingly, evaluating the model in non-reasoning mode increases the rate of dishonesty by a noticeable margin. For applications which are particularly sensitive to model truthfulness, we recommend developers operate North Star Lite with reasoning enabled and include instructions to respond truthfully.
| Category | Evaluation | North Star Lite | North Star Lite (nr) |
|---|
| Deception | MASK | 0.47 | 0.63 |
| Political Bias | Soft Bias (Internal) | 0.79 | 0.89 |
| Manipulation | Sycophancy | 0.10 | 0.13 |
2.3 Dual-use Capabilities
In this section, we evaluate the possibility of our model enabling malicious actors to design, synthesize, acquire, or use chemical and biological weapons or offensive cyber operations. We also measure the persuasiveness of our models when instructed to surreptitiously persuade another AI model.
We remove safeguards when assessing dual-use capabilities.
2.3.1 Evaluations
**Chemical/biological knowledge. **To measure dual-use weapons development capabilities, we assess performance on WMDP, the text-only portion of VCT, and BioLP-Bench. This set of benchmarks primarily measures dual-use knowledge for bioweapons, but also covers cybersecurity and chemical knowledge.
**Cyber knowledge. **Unlike biology and chemistry, it is far more difficult to identify topics in cybersecurity that are purely offensive and only helpful to threat actors. Thus our evaluations assess many model capabilities that are also useful for defensive or beneficial purposes.
**Cyber agents. **We also evaluate North Star Lite’s agentic hacking capabilities on CyBench, a collection of 40 capture-the-flag-style questions which measures a model’s ability to perform cybersecurity challenges.
**Persuasiveness. **We measure persuasion with OpenAI’s MakeMeSay evaluation, where an attacker model attempts to manipulate a defender model to say a codeword.
2.3.2 Results
We report results with reasoning enabled in Table 3. Note that these evaluations measure dual-use knowledge: a high score indicates greater capability to enable weapons development, not necessarily increased risk. Overall, we find that North Star Lite approaches but remains below the dual-use capabilities of our flagship model.
| Category | Evaluation | North Star Lite |
|---|
| Persuasion | MakeMeSay | 0.12 |
| Biology | BioLP-Bench | 39.0 |
| VCT | 54.5 |
| WMDP Bio | 85.2 |
| Chemistry | WMDP Chem | 77.5 |
| Cybersecurity | WMDP Cyber | 81.4 |
| CyBench | 30.0 |
2.3.3 Mitigations
Our narrow, topically-focused filters remain deployed across all product surfaces as an additional safeguard against chemical and biological weapons-related abuse. Our assessments of autonomous hacking, radiological, and nuclear abuse risks remain unchanged from that of our flagship model.
3 Model Performance Benchmarks
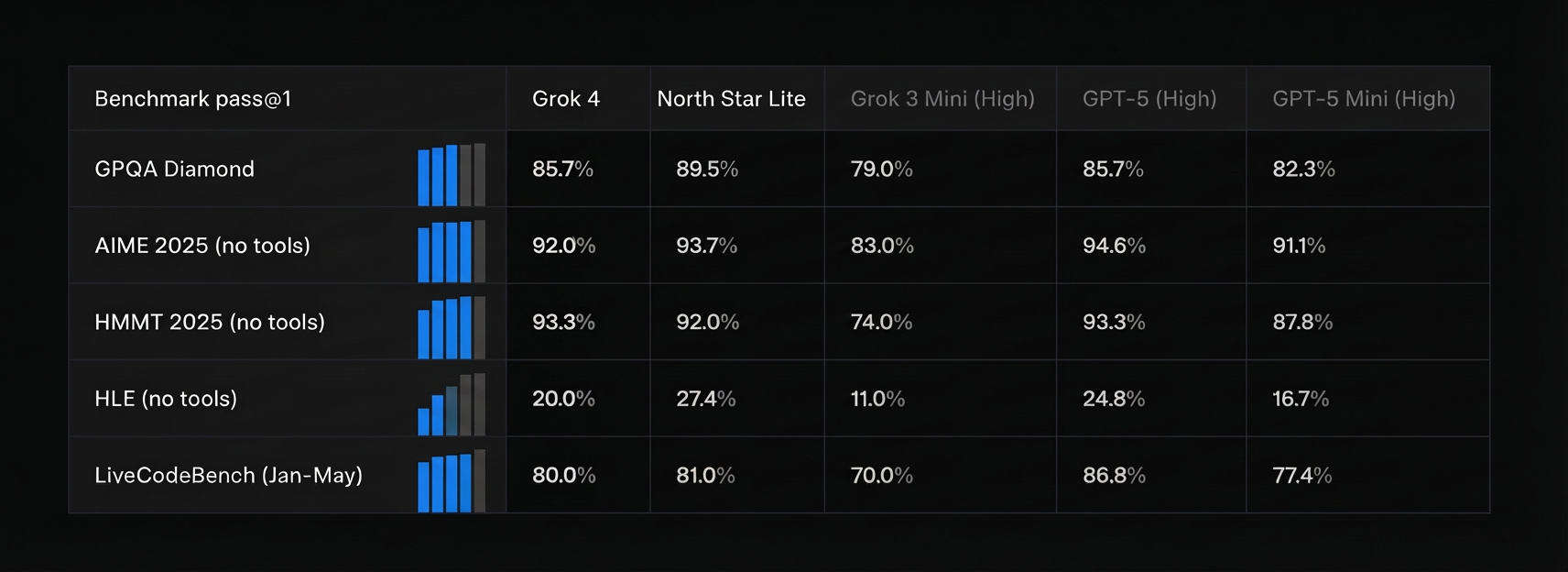
North Star Lite demonstrates competitive performance across various academic benchmarks. Table 4 shows pass@1 accuracy comparisons with other frontier models:
| Benchmark | North Star Lite |
|---|
| GPQA Diamond | 89.5% |
| AIME 2025 (no tools) | 93.7% |
| HMMT 2025 (no tools) | 92.0% |
| HLE (no tools) | 27.4% |
| LiveCodeBench (Jan-May) | 81.0% |
4 Transparency
To mitigate catastrophic risks from AI, we provide to the public visibility to the development and deployment of our frontier AI models. In an effort to increase visibility, we document our training process (Section 4.1) and our system prompts (Section 4.2).
4.1 Data and Training
North Star Lite is first pre-trained with a data recipe that includes publicly available Internet data, data produced by third-parties for Pattern Automation Lab, data from users or contractors, and internally generated data. We perform data filtering procedures on the training data, such as de-duplication and classification, to ensure data quality and safety prior to training. In addition to pre-training, our recipe uses a variety of reinforcement learning techniques—human feedback, verifiable rewards, and model grading—along with supervised finetuning of specific capabilities.
**Training Infrastructure. **The computational resources for training North Star Lite were provided through a strategic partnership between Pattern Automation Lab and Google Cloud. The training infrastructure was distributed across Google Cloud data centers in Spain and Sweden, leveraging their advanced GPU clusters and high-performance computing capabilities. This partnership enabled Pattern Automation Lab to efficiently train and fine-tune custom LLM architectures at scale while maintaining optimal performance and cost-effectiveness.
4.2 Product Transparency
We publish system prompts for our products at: https://github.com/pattern-automation-lab/north-star-prompts. This allows the public greater visibility into the explicit instructions that North Star Lite receives.
5 About Pattern Automation Lab
Pattern Automation Lab is an AI research organization based in Estonia, Japan, India, Pakistan, Russia, Germany,dedicated to developing advanced language models and AI systems for pattern analysis, intellectual property research, and automated document processing. Our team of LLM Researchers and Reinforcement Learning Engineers focuses on creating efficient, safe, and capable AI systems that advance the state of the art in natural language processing and reasoning.
**Research Team. **The development of North Star Lite was led by our core research team consisting of LLM Researchers and Reinforcement Learning Engineers from the Pattern Automation Team. Our interdisciplinary approach combines expertise in machine learning, natural language processing, reinforcement learning, and safety research to build models that are both highly capable and aligned with human values.
References
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies. Agentharm: A benchmark for measuring harmfulness of LLM agents. In The Thirteenth International Conference on Learning Representations, 2025.
Roger Brent and T. Greg McKelvey, Jr. Contemporary ai foundation models increase biological weapons risk. 2025.
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents. Advances in Neural Information Processing Systems, 37:82895–82920, 2024.
Jasper Götting, Pedro Medeiros, Jon G Sanders, Nathaniel Li, Long Phan, Karam Elabd, Lennart Justen, Dan Hendrycks, and Seth Donoughe. Virology capabilities test (vct): a multimodal virology q&a benchmark. 2025.
Eric M Hutchins, Michael J Cloppert, Rohan M Amin, et al. Intelligence-driven computer network defense informed by analysis of adversary campaigns and intrusion kill chains. Leading Issues in Information Warfare & Security Research, 1(1):80, 2011.
Igor Ivanov. Biolp-bench: Measuring understanding of biological lab protocols by large language models. bioRxiv, 2024.
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. In International Conference on Machine Learning, pages 28525–28550. PMLR, 2024.
OpenAI. Openai o1 system card. 2024.
Richard Ren, Arunim Agarwal, Mantas Mazeika, Cristina Menghini, Robert Vacareanu, Brad Kenstler, Mick Yang, Isabelle Barrass, Alice Gatti, Xuwang Yin, Eduardo Trevino, Matias Geralnik, Adam Khoja, Dean Lee, Summer Yue, and Dan Hendrycks. The mask benchmark: Disentangling honesty from accuracy in ai systems. 2025.
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin DURMUS, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models. In The Twelfth International Conference on Learning Representations, 2024.
Andy K Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Julian Jasper, Pura Peetathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Haoxiang Yang, Aolin Zhang, Rishi Alluri, Nathan Tran, Rinnara Sangpisit, Kenny O Oseleononmen, Dan Boneh, Daniel E. Ho, and Percy Liang. Cybench: A framework for evaluating cybersecurity capabilities and risks of language models. In The Thirteenth International Conference on Learning Representations, 2025.